业界 作者:SegmentFault 2021-10-25 17:21:13 阅读:1066
factorizeQueue的控制走到了factory.create。这个时候就开始了reslove过程。NormalModuleFactory 内部 beforeResolve,factorize,resolve, afterResolve 这几个钩子。module.exports = {
mode: 'production',
entry: './src/index.js',
output: {
filename: 'main.js',
path: path.resolve(__dirname, 'dist'),
},
module: {
rules: [
{
test: /\.(js?|tsx?|ts?)$/,
use: [
{
loader: 'babel-loader',
},
],
},
]
},
resolve: {
extensions: ['.js', '.ts'],
alias: {
demo: path.resolve(__dirname, 'src/second'),
},
},
};factory.create开始,这里的 factory 是之前 addModuleTree 获取到的 NormalModuleFactory
NormalModuleFactory 先触发了其内部的 beforeResolve 钩子,然后在回调里执行了 factorize 钩子函数。factorize 钩子内有又调用了resolve。beforeResolve -> factorize -> resolvebeforeResolve 没找到之前注册过的地方,看起来什么都没干,也有可能是我没找到
factorize 之前在 ExternalModuleFactoryPlugin插件中注册过,这里会处理下external的信息。
resolve 钩子注册在NormalModuleFactory内部,用于解析这个module,生成对应的loader和依赖信息,这里的重点就在resolve
resolve 钩子先调用了this.getResolver("loader") 返回loaderResolver,这个可以理解为是解析loader的方法。调用到了 ResolverFactory里的get方法
判断是否有对应类型的缓存
创建 resolveOptions,
调用require("enhanced-resolve").ResolverFactory创建了一个 resolver,然后返回 NormalModuleFactory继续执行代码。
const loaderResolver = this.getResolver("loader");
loaderResolver暴露了一个resolver方法,用于解析loader。defaultResolve这个方法,这里会根据webpack配置文件中的resolve选项,生成一个 normalResolver。同样的,这个normalResolver也是require("enhanced-resolve").ResolverFactory的实例,也暴露出了一个resolve方法。const normalResolver = this.getResolver(
"normal",
dependencyType
? cachedSetProperty(
resolveOptions || EMPTY_RESOLVE_OPTIONS,
"dependencyType",
dependencyType
)
: resolveOptions
);normalResolver 和一些上下文信息传给resolveResource方法,这里最终会调用到node_modules/enhanced-resolve/lib/Resolver.js的doResolve。this.resolveResource(
contextInfo,
context,
unresolvedResource,
normalResolver,
resolveContext,
(err, resolvedResource, resolvedResourceResolveData) => {
if (err) return continueCallback(err);
if (resolvedResource !== false) {
resourceData = {
resource: resolvedResource,
data: resolvedResourceResolveData,
...cacheParseResource(resolvedResource)
};
}
continueCallback();
}
);doResolve返回的resolvedResource和resolvedResourceResolveData一起拼装成resourceData。我们在后续解析loader的时候还会用到这个。resourceData数据结构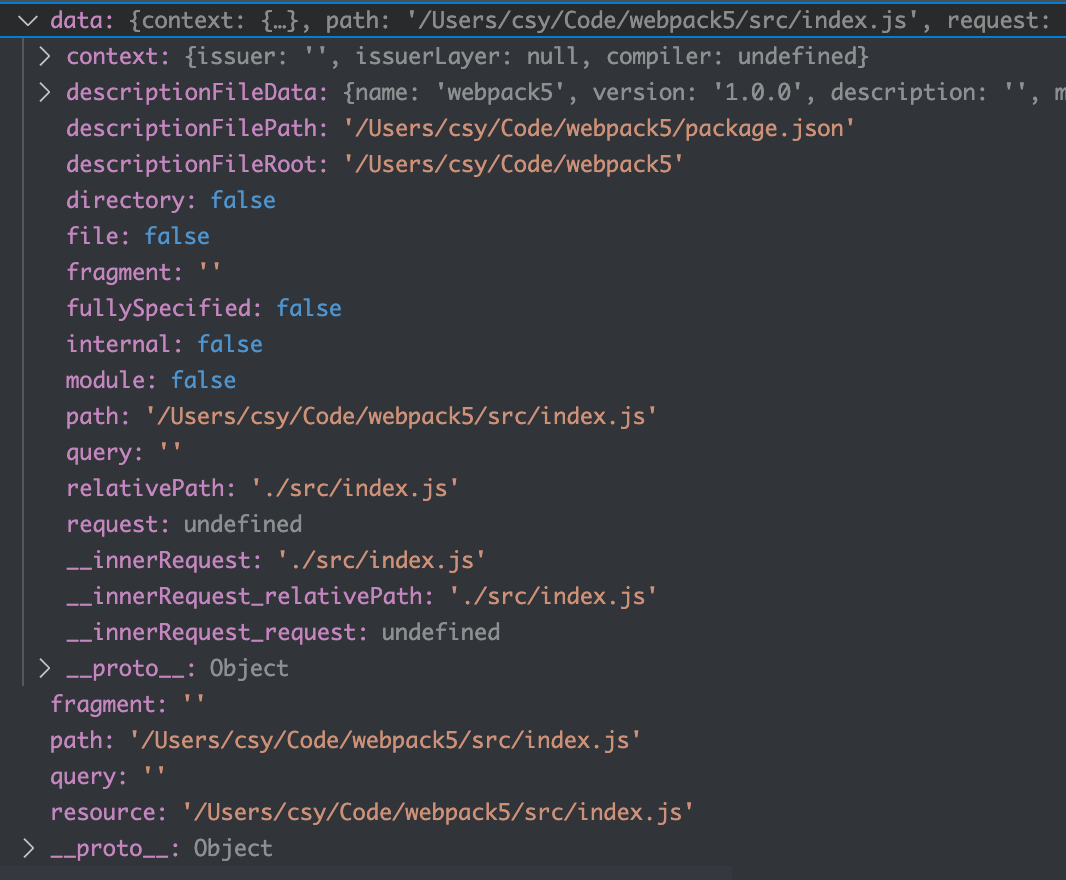
resolvedResource的回调里继续执行const result = this.ruleSet.exec({
resource: resourceDataForRules.path,
realResource: resourceData.path,
resourceQuery: resourceDataForRules.query,
resourceFragment: resourceDataForRules.fragment,
scheme,
assertions,
mimetype: matchResourceData
? ""
: resourceData.data.mimetype || "",
dependency: dependencyType,
descriptionData: matchResourceData
? undefined
: resourceData.data.descriptionFileData,
issuer: contextInfo.issuer,
compiler: contextInfo.compiler,
issuerLayer: contextInfo.issuerLayer || ""
});
rules得到需要的loader,这个例子里,我们的result是
result的遍历,生成useLoadersPost, useLoaders, useLoadersPre。resolveRequestArray得到postLoaders, normalLoaders, preLoaders。this.resolveRequestArray(
contextInfo,
this.context,
useLoaders,
loaderResolver,
resolveContext,
(err, result) => {
normalLoaders = result;
continueCallback(err);
}
);
postLoaders和preLoaders,这里只有normalLoaders。resolveRequestArray内部调用loaderResolver.resolve解析useLoaders,最后结果就是把result里的loader替换成了对应的真实文件地址。{
ident:undefined
loader:'/Users/csy/Code/webpack5/node_modules/babel-loader/lib/index.js'
options:undefined
}continueCallback处理下已经生成好的数据,首先是对loader的合并。把postLoaders, normalLoaders, preLoaders这几个合并。然后assign一下data.createData, 这个data来自于钩子的入口传入的data。Object.assign(data.createData, {
layer:
layer === undefined ? contextInfo.issuerLayer || null : layer,
request: stringifyLoadersAndResource(
allLoaders,
resourceData.resource
),
userRequest,
rawRequest: request,
loaders: allLoaders,
resource: resourceData.resource,
context:
resourceData.context || getContext(resourceData.resource),
matchResource: matchResourceData
? matchResourceData.resource
: undefined,
resourceResolveData: resourceData.data,
settings,
type,
parser: this.getParser(type, settings.parser),
parserOptions: settings.parser,
generator: this.getGenerator(type, settings.generator),
generatorOptions: settings.generator,
resolveOptions
});
getParser和getGenerator, 这两个方法返回的是对应文件的解析器和构建模板的方法。按照当前示例,返回的是JavascriptParser和JavascriptGenerator。createData将被用于createModule。NormalModuleFactory的afterResolve钩子后const createData = resolveData.createData;
this.hooks.createModule.callAsync(//something)
module!module resolve 流程用于获得各 loader 和模块的绝对路径等信息。
在resolver钩子里,先通过enhanced-resolve获取 loaderResolver,提供 resolve 方法
在defaultResolve 方法里,获取 normalResolver, 提供 resolve 方法。
解析unresolvedResource,得到文件的绝对路径等信息
根据rules得到 loader
使用 loaderResolver 得到loader的绝对路径等信息
合并 loader, 拼接数据,
调用NormalModuleFactory的afterResolve钩子,结束resolve流程。







Copyright © 2015 KnowSafe All rights reserved.
公司地址:成都市高新区天府大道北段1700号
业务邮箱:Sales@knowsafe.com











