业界 作者:CSDN 2021-11-15 17:18:33 阅读:1025

“如无必要,勿增实体”的奥卡姆剃刀原则,从IT人士的角度来看就是“只要能运行,就千万不要改”,而且各种“杀个程序员祭天”,“耽误工期遭索赔”等事件依旧层出不穷,IPv4只要还能勉强运行一天,那么IPv6就得晚上位一天。

CSDN付费下载自东方IC
但问题是IPv4的资源真撑不住几天了,截至2021年2月26日,APNIC地址池仅剩余折合0.23个A的IPv4地址,最多再有两年就会盆干碗净一点不剩了。而且IPv6目前发展得也很不错,在基础软件中,Windows、Linux已经支持IPv6近15年了,目前已经非常稳定,Docker容器天然支持IPv6,K8s也已经稳定支持IPv6,但是再好的技术,没有改造动力也出不来,虽然IPv6替换口号喊得震天响,但实际的进展却总不如人意。

IPv6的进度条
IPv6目前在各技术栈当中已经获得了广泛的支持,但是覆盖面还有待提升,比如在基础软硬件平台中的操作系统方面,目前仅有75%左右节点会默认安装IPv6协议栈,有65%左右支持DHCPv6,50%左右支持ND RNDSS;而在网络设备方面,虽然目前绝大多数的设备均已经支持IPv6协议,但在无线WIFI尤其是家庭无线WIFI等实际场景中,默认使用IPV6地址的无线路由器还不足20%;在应用侧对于IPv6的支持度会好一些,如Bing、雅虎、淘宝等众多网站或者APP均已经宣布永久支持IPv6,但由于实际使用IPv6的终端用户数量不足,因此目前的互联网还几乎是IPv4的世界。
但最近元宇宙的突然兴起,让情况突然发生了变化,科技龙头脸书改名Meta,以坚定自身的转型决心,罗永浩老师也宣传在还完债之后要从直播界回归到科技界做元宇宙的创业项目。当然这里不想讨论关于元宇宙的话题,但是元宇宙肯定无从构建在一个只有50亿个地址池的IPv4空间上。

资源池大就完事了
IPv6全球路由地址有230亿亿(261)个,号称可以给地球上每粒沙子分配一个IP,60亿人口和500亿物联网终端,在IPv6协议看来根本不是什么问题,彻底解除由于IP资源池大小限制网络规模的拓展,这才能和元宇宙的宏大愿景相对应。

而且IPV6还能带来更好的上网体验,如果有读者经常使用手机银行等金融APP可能会发现这样一个现象,那就是当WIFI与数据连接发生切换时,手机银行的登陆状态往往也会改变,但移动IPv6协议改变了这种情况,IPv6的移动终端在改变地理位置时,即使分配到的IPv6地址发生变化,原有的连接也不会被Terminate。
IPv6报头还新定义了流标签字段,路由器可根据源宿地址+流标签唯一标识一条端到端的IP业务流。实现有序转发,这对于QoE要求高的短视频等赛道来说可以大幅提升用户的使用体验。

别看报文长,但他效率高
IPv6报文头中目的IP等字段要比IPV6要长,但却是定长的,网络设备的算力载体本质上也是CPU处理器,这就使它也逃不开CPU体系架构的制约,在现代的指令流水线体系中,定长字段就是比变长字段更具效率优势。
我们知道CPU的每个动作都需要用晶体震荡而触发,想执行一条指令需要取指、译码、取操作数、执行以及取操作结果等若干步骤,而每个步骤都需要一次晶体震荡才能推进,因此在流水线技术出现之前执行一条指令至少需要5到6次晶体震荡周期才能完成。

由于取指、译码这些模块其实在芯片内部都是独立的,那么只要将多条指令的不同步骤放在同一时刻执行,比如指令1取指,指令2译码,指令3取操作数等等,就可以大幅提高CPU执行效率:
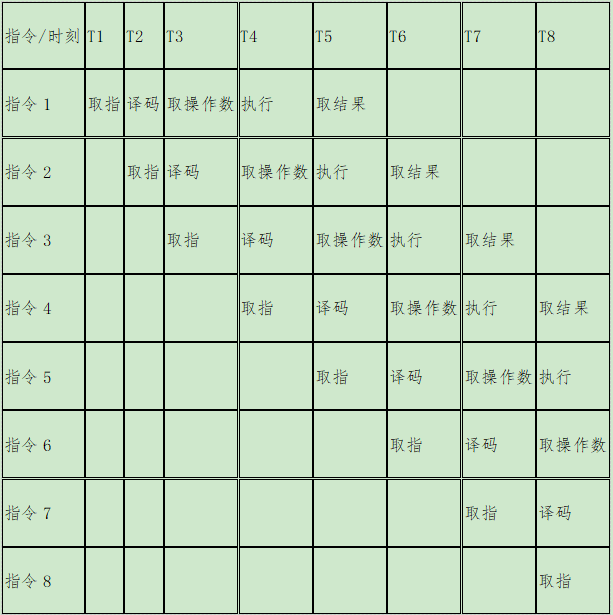
但是指令流水线也带来了分支预测的问题,一旦一条提令不是后续执行所在的if分支,但处理器却错误的把它放在了流水上,那么这就会造成处理器的空转,带来极强的惩罚效应。
因此这也让那些不涉及if-else分支定长报文解析可以在现代CPU架构下获得更高的效率,因为非定长的报文肯定要做if判断来决定报文的解析方式,而一旦分支预测失败,那就会迎接流水线执行效率下降的惩罚,比如指令5本是不应该执行的分支代码,如果在T7也就是指令3取结果时才发现这一预测错误,那么还很可能会拖累指令6、指令7也全部陷入预测失效。那么,下一时刻T8指令8才刚刚开始译码,这会造成整个流水线的效率大幅下降。在之前的文章《M1 MAX暴击,倚天补刀》中曾经介绍过,基于ARM这种RISC架构的处理器其最大的优势在于可以把指令解码器做到极致,从而平衡功耗与性能之间的关系。
所以我们不能认为IPV6的IP地址长度更长,转发效率就会低,真实的情况恰恰相反,IPV6要比V4路由器转发效率高得多!

神之一笔—路由聚合策略
在Facebook要All In元宇宙改名Meta之前不久,其实他们刚刚遇到了由于广域路由协议BGP造成的全球范围宕机问题。在路由设计方面,IPv6也比IPv4要领先很多,IPv6在设计之初就认为IP体系是聚合的(Aggregation),可自顶向下树状分配,路由器可集合路由条目,瘦身路由表。本质上讲路由算法就是要找到从地点A到地点B最短距离的旅行规划问题。而针对这个问题早就有经典算法dikjstra解决。为了说清这个IPv6路由聚合(Aggregation)的好处,下面我们先把dikjstra旅行算法做一下介绍。
旅行规划的题目可以归结为以下说法,用户有一张自驾旅游路线图显示了城市及公路的数量,高速公路长度、过路费。现在要通过一个算法,找一条出发地和目的地之间的最短路径。如果有若干条路径都是最短的,那么需要输出最便宜的一条路径。
实际在网络路由规划中,城市代表着网络上的节点,调整公路代表网络上的通道,公路长度一般代表网络通道的传输性能,过路费用的数据在实际工程中可能代表着线路质量等参数。
示例代码中的变量说明:N、M、S、D分别代表城市个数、调整公路条数、旅行者起始城市编号、旅行者目的地城市编号,其中N(2≤N≤500)是城市的个数,三维数组g存储高速公路的信息,记录起始城市、终点城市、高速公路长度、收费额,如g[i][j][1]代表编号为i的城市到编号为j的城市之间的距离,g[i][j][2]代表编号为i的城市到编号为j的城市过路的费用,哈希表Path记录由旅行者的起始城市S到编号为i的城市之间的最短路径信息,如起始城市S到i之间经过j、k最短,那么Path[i]的值应该是[j,k],注意j、k对于顺序敏感。Dist数据记录旅行者起始市S到编号为i的城市之间的距离数值,cost数据记录旅行者起始市S到编号为i的城市之间的花费,到Known数组记录城市是否被算法遍历确认,
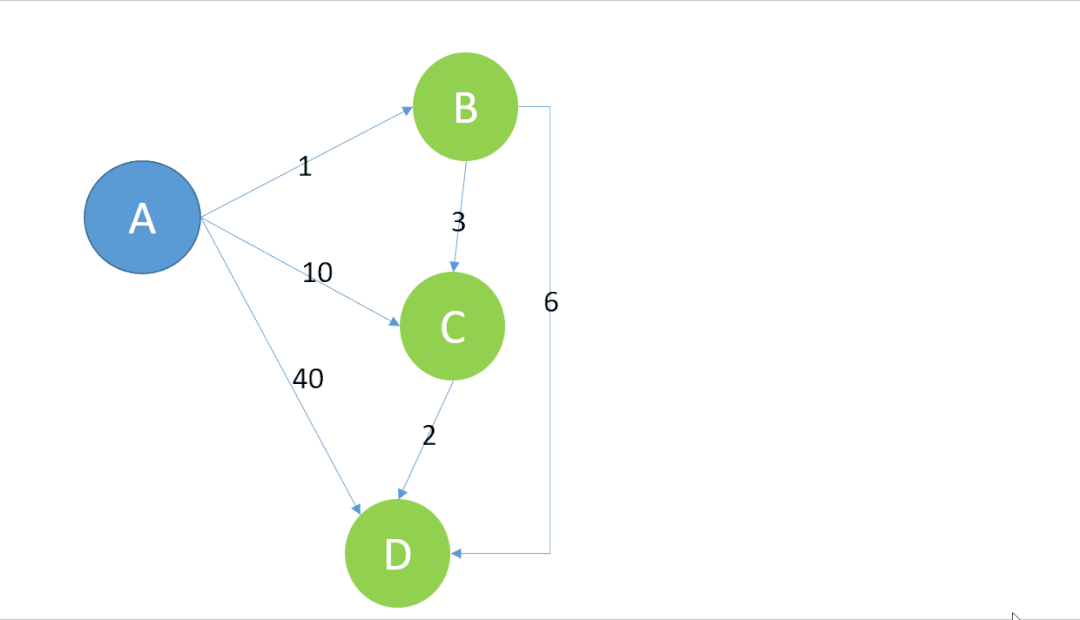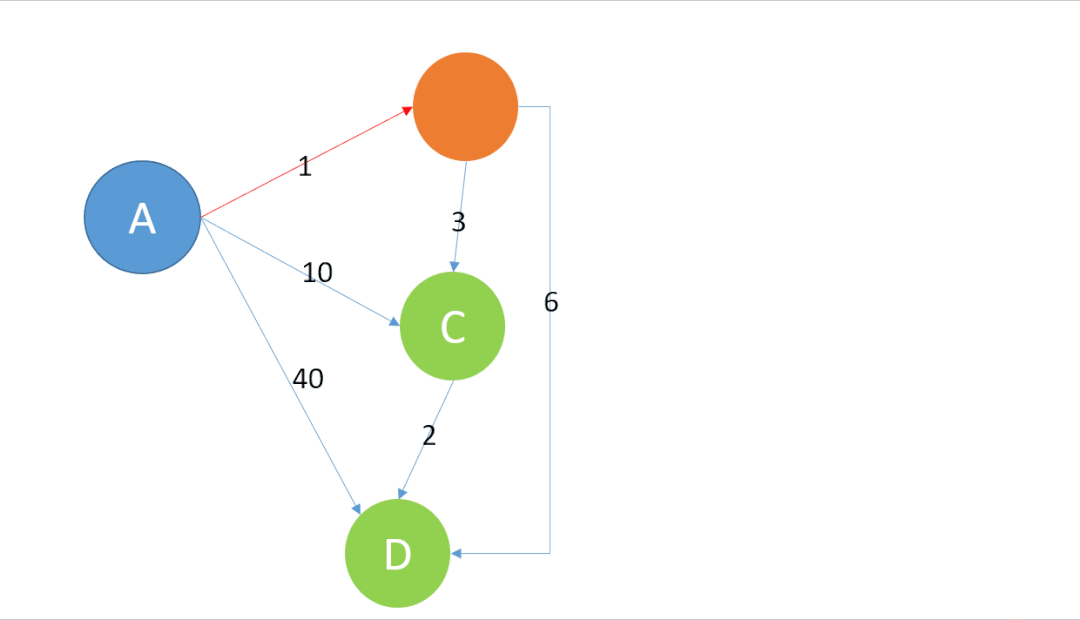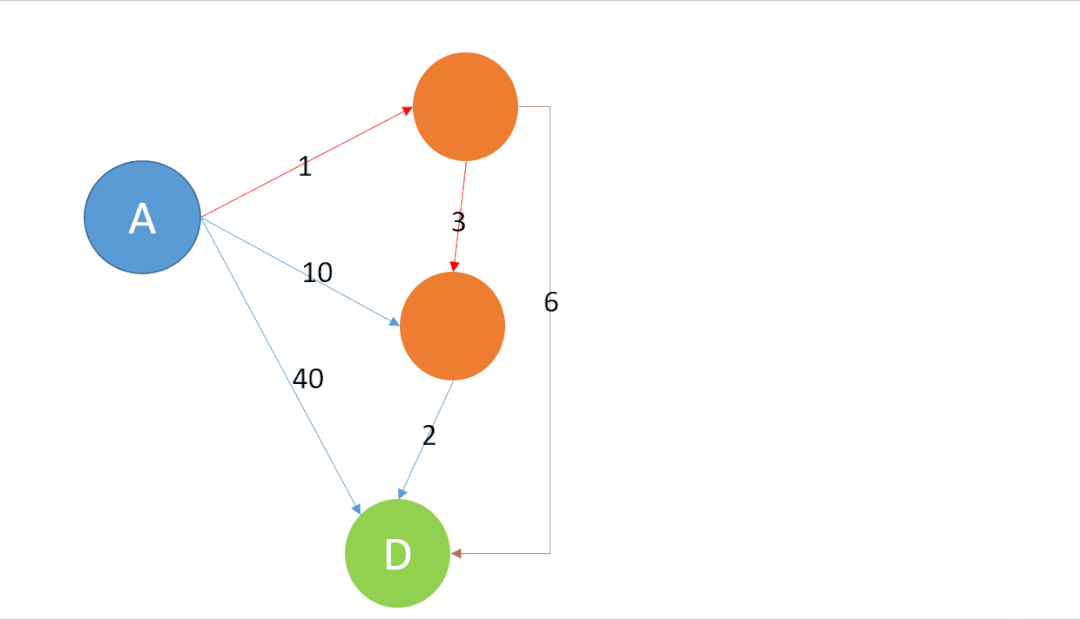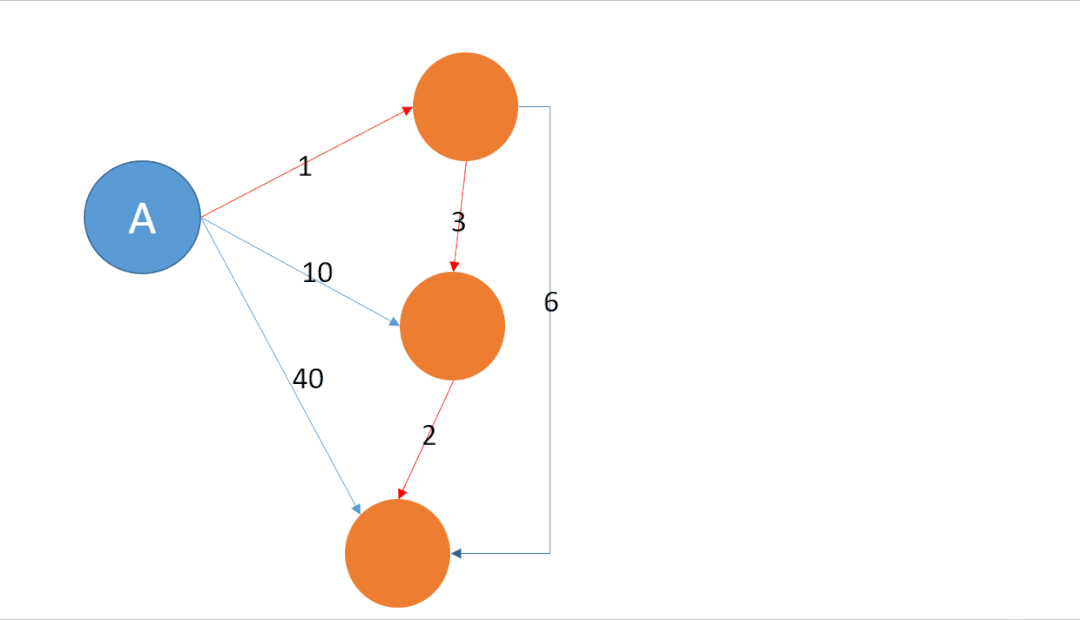
比如经典路由协议OSPF (Open Shortest Path First)中的SPF最短路径优先其实就非常清楚的表达出了dijkstra算法的精髓,实际上这个算法就是不断找到离起点S最近的未确认城市A,并尝试通过A中转能否优化到S的距离,如下图所示:
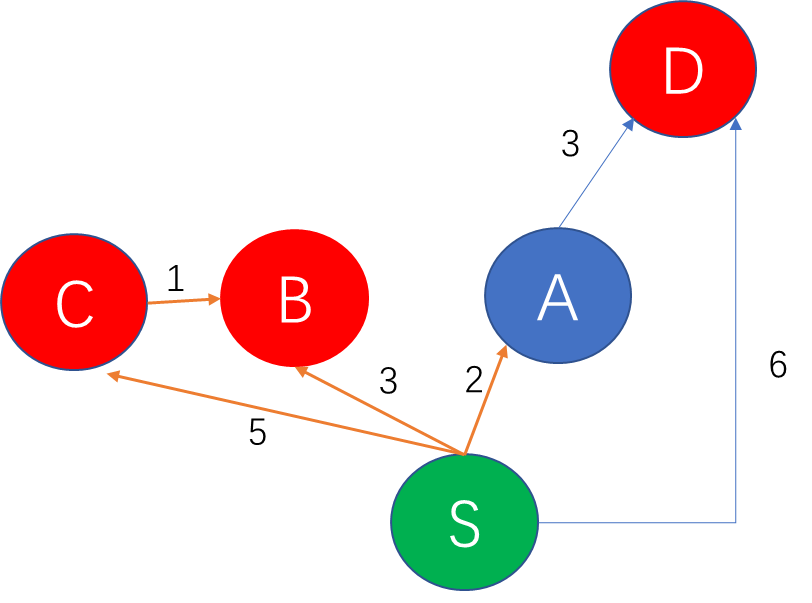
注:绿色代表起点城市,蓝色代表known状态已经迭代的城市,红色代表unknown状态的城市
dijkstra算法首先要做的就是找到所有未知节点中与起始地S最近的城市A,因为经城市A现在离S最近,那么经城市A中转,就有可能会缩短S到其它目的地城市D的距离。比如上图当中S到A的距离是2,截止目前是S到其它城市中距离最短的一条路径,那么经A跳转则有可能获得一个比从S直接到D更短的路径。在上图例中在使用A行过一轮迭代以后,S到D的距离可以由直接访问的距离6,优化为经A中转的距离5。在完成一轮优化后A节点会被记录为known的状态,接下来会用非known状态的节点中找到离起始点最近的那个做下一轮迭代。直到所有城市全部状态全部都是known为止。
以go语言为例,代码如下:
package mainimport ("fmt""strconv")const N int = 4const INF int = 501var g [N][N][2]intvar dis [N + 1]intvar pay [N]intvar known [N]boolvar n, m, s, d, i, j, t1, t2, v intvar path map[int][]intfunc findMinDistance() {disMin := INFfor i := 0; i < n; i++ {if !known[i] && dis[i] < disMin {v = idisMin = dis[i]}}}func dijkstra() {for k := 1; k < n; k++ {findMinDistance() //先把状态为unknown的节点中到起点距离最短的点//接下来按照之前介绍的算法使用距离最短的节点对其它节点进行优化known[v] = truefor i = 0; i < n; i++ {if !known[i] && g[v][i][0] < INF {if dis[v]+g[v][i][0] < dis[i] {dis[i] = dis[v] + g[v][i][0]pay[i] = pay[v] + g[v][i][1]footPrint := path[v]path[i] = append(footPrint, v)} else if !known[i] && dis[v]+g[v][i][0] == dis[i] && pay[v]+g[v][i][1] < pay[i] {pay[i] = pay[v] + g[v][i][1]}}}}}func main() {//以下是初始化城市个数、高速公路条数、起始城市、终点城市的工作path = make(map[int][]int)n = 4m = 5s = 0d = 3//初始化时先把path对应的路径置为空for i := 0; i < n; i++ {s1 := make([]int, 0)path[i] = s1}//初始化化时先把g数组对应的路径置为空for i = 0; i < n; i++ {for j := 0; j < n; j++ {g[i][j][0] = INFg[i][j][1] = INF}}keyInput := [...][6]int{{0, 1, 1, 20}, {1, 2, 3, 30}, {0, 3, 40, 10}, {0, 2, 10, 20}, {2, 3, 2, 20}, {1, 3, 6, 20}}//把道路信息写入g数组for ; m > 0; m-- {i = keyInput[m-1][0]j = keyInput[m-1][1]t1 = keyInput[m-1][2]t2 = keyInput[m-1][3]g[i][j][0] = t1g[j][i][0] = t1g[i][j][1] = t2g[j][i][1] = t2}//fmt.Println(g)//初始化known数组全部置为false状态for i = 0; i < N; i++ {known[i] = false}//初始化起点到编号为j节点的距离及花费信息for j = 0; j < n; j++ {dis[j] = g[s][j][0]pay[j] = g[s][j][1]}dis[s] = 0pay[s] = 0dis[n] = INFdijkstra() //调用dijkstra算法if dis[d] < INF {fmt.Println("Distance is " + strconv.Itoa(dis[d]) + ",The cost is " + strconv.Itoa(pay[d]))fmt.Println("Path is", path[d])}}
用动图展示上述代码的运行过程如下:

复杂度O(n2)-来自于底层算法的制约
Dijkstra本质上是旅行者算法而不是网络路由算法。简单来讲dijkstra是为旅行者而设计的,站在旅行者的角度去考虑问题,但是从网络的实际使用情况上看,算法中的旅行者对应应用层的数据包,按照网络结构层的分工界限,应用层只负责提供目的IP地址,具体如何路由到目的IP,完全不是数据包的发送方需要关心的问题。
而站在网络设备的角度上看,假如上面例程中的城市A是上台路由器,那么它只需要掌握最优路径上下一个城市C的路由信息就可以了,掌握整个路径的全貌,费时费力不说,也没有必要。
更为关键的是Dijkstra算法的时间复杂度接近于O(n2),这也决定了IPv4那种散乱的IP分配方式在互联网终端越来越多的情况完全难以为继。我们刚刚也讲了Dijkstra每步迭代的之间是有前后顺序关系的,很难像搜索那样进行分布式并行计算改造。因此这也就使得路由协议必须要限制管理节点的个数,因为如果要给整个互联网上几十亿节点跑一遍Dijkstra算法,显然不是一种可行的计算方案。
因此这里IPv6把路由聚合的策略其实就是把网络进行分区的方案。也就是说网络数据包要先到达某一区,进区之后再通过内部网关协议IGP只处理区域内部的网络关系。IPv6在路由划分上的清晰策略也是它能够取代IPv6的最重要原因之一。
IPv6包头还有很多非常有意义的扩展,天然支持IPSEC,安全性得以提升,也增强了对组播和QoS的支持。不过目前我们对IPv6的应用还停留在互联网边界层面,对它的这些增强特性使用的还不多,但是元宇宙应该是IPv6普及之路上的一大契机,未来几何让我们拭目以待。
作者:马超,CSDN博客专家,阿里云MVP、华为云MVP,华为2020年技术社区开发者之星。
☞腾讯回应“接入抖音平台”;苹果因搜查员工赔偿近3000万美元;新版Win11黑屏重新改回蓝屏 | 极客头条
(本文阅读时间:6分钟)当元宇宙让虚拟和物理的边界愈加模糊,全球达人正竞相成为新世界的“头号玩家”——虚拟房产一周交易额超1亿美元;艺术展、音乐节、游戏竞赛等在虚拟平台Decentraland上百花齐
2022年6月28日,由中国贸促会商业行业委员会、中国国际商会商业行业商会指导,中国国际商会商业行业商会沉浸式文旅产业委员会主办,北京多牛互动传媒股份有限公司承办的“元宇宙创新论坛”在线上成功召开。本
hi188 | 编辑本周大新闻,AR方面,Khronos牵头成立元宇宙标准联盟;ARKit应用超1.4万个;爱普生发布BT-45C AR眼镜;宜家虚拟家装工具Kreativ;沃尔玛App加入AR预览功
Copyright © 2015 KnowSafe All rights reserved.
公司地址:成都市高新区天府大道北段1700号
业务邮箱:Sales@knowsafe.com


















